Introduction
The Importance of Sea Transportation

Sea transportation is one of the modes that are quite helpful for human activities, especially in distributing logistics (K. Verawati et al., 2022)
All types of activities from sea transportation should be monitored so that illegal activities do not occur that can harm one party. However, in detecting this marine vessel, an instrument that has good accuracy is needed to carry out fast information processing of marine transportation detection, especially this ocean liner (J. Wu et al., 2021).
Model Detection
Object Detection Model to Detect Marine Vessels Activities

In connection with the importance of detecting ship objects as one of the main modes of sea transportation, especially in Indonesia, technology or models are needed that can easily detect certain objects, in this case, they are objects of sea vessels. Redmon, et al. (J. Redmon et al., 2016) have made preliminary instructions on a model that can be used to detect objects, which is named YOLO (You Only Look Once), where the YOLO model is a model with one-step detection, where the model will be more efficient to carry out detection when compared to two-step detection such as RCNN, Faster RCNN, and the like which require two stages in detecting the main object to be detected (S. Luo et al., 2022) so that in this study the YOLO model will be used as a basis for detecting marine objects that are the main objects in their detection.
Model Architecture
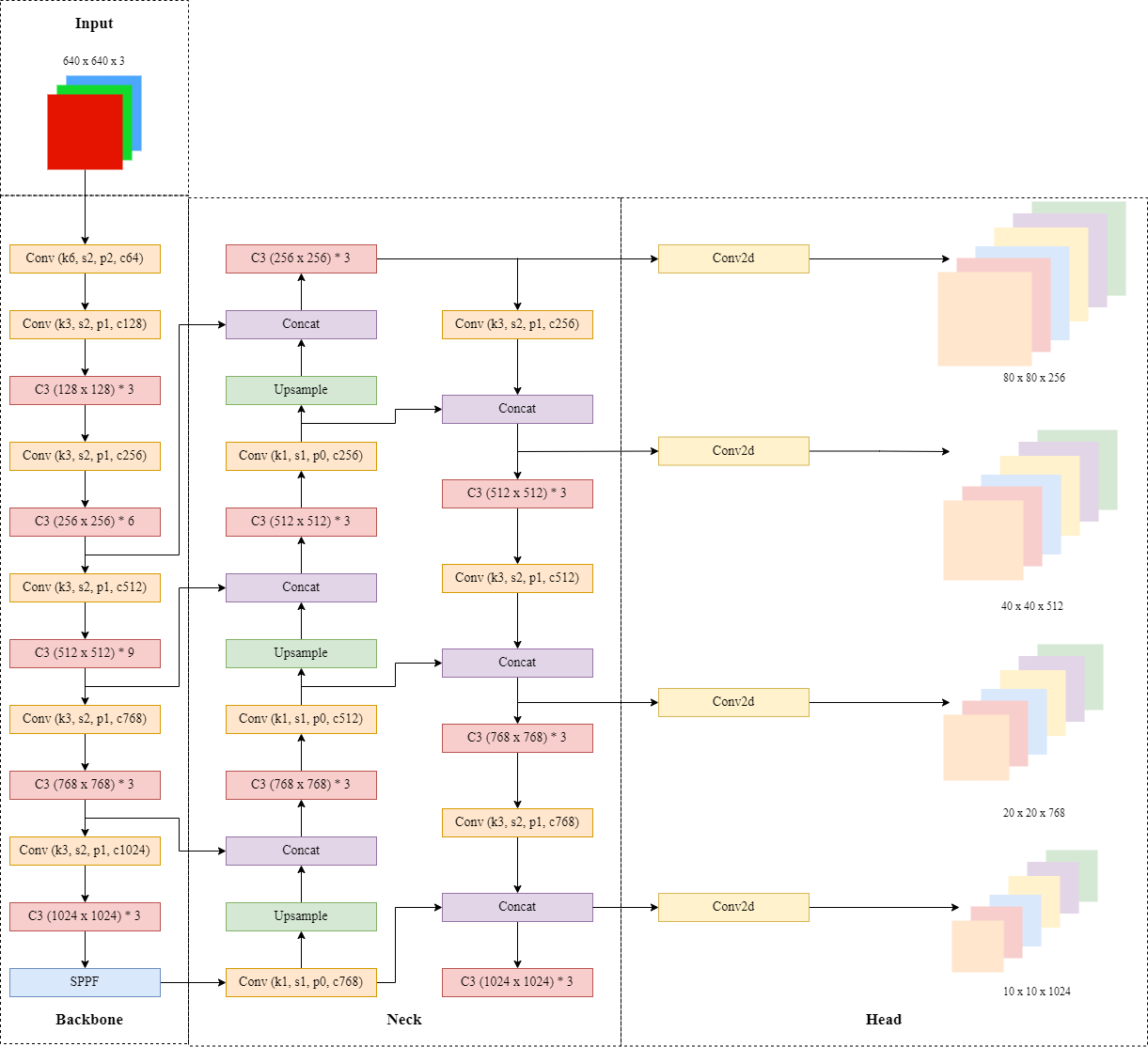
YOLOv5x6 Architecture
A special architecture of the YOLOv5 version of 6.0, where this model has a higher level of complexity compared to other YOLOv5 derivatives. In the picture, it is clear that in the backbone, there is an addition of a CSP (Cross-Stage-Partial) function in the section, followed by SPPF (Spatial Pyramid Pooling-Faster) on the neck of the model, and also in this section, the concept of the Darknet-53 is used as a derivative of the YOLOv4 model (A. Bochkovskiy et al., 2020). With this SPPF, the size of the image received by the model can vary, and later when the training process is carried out, size adjustments will be made according to the parameters that have been set at the time of model construction. After that, with Conv2d, the model will detect objects at the image input according to a very wide range of points, namely 10 x 10, 20 x 20, 40 x 40, and 80 x 80.
Dashboard
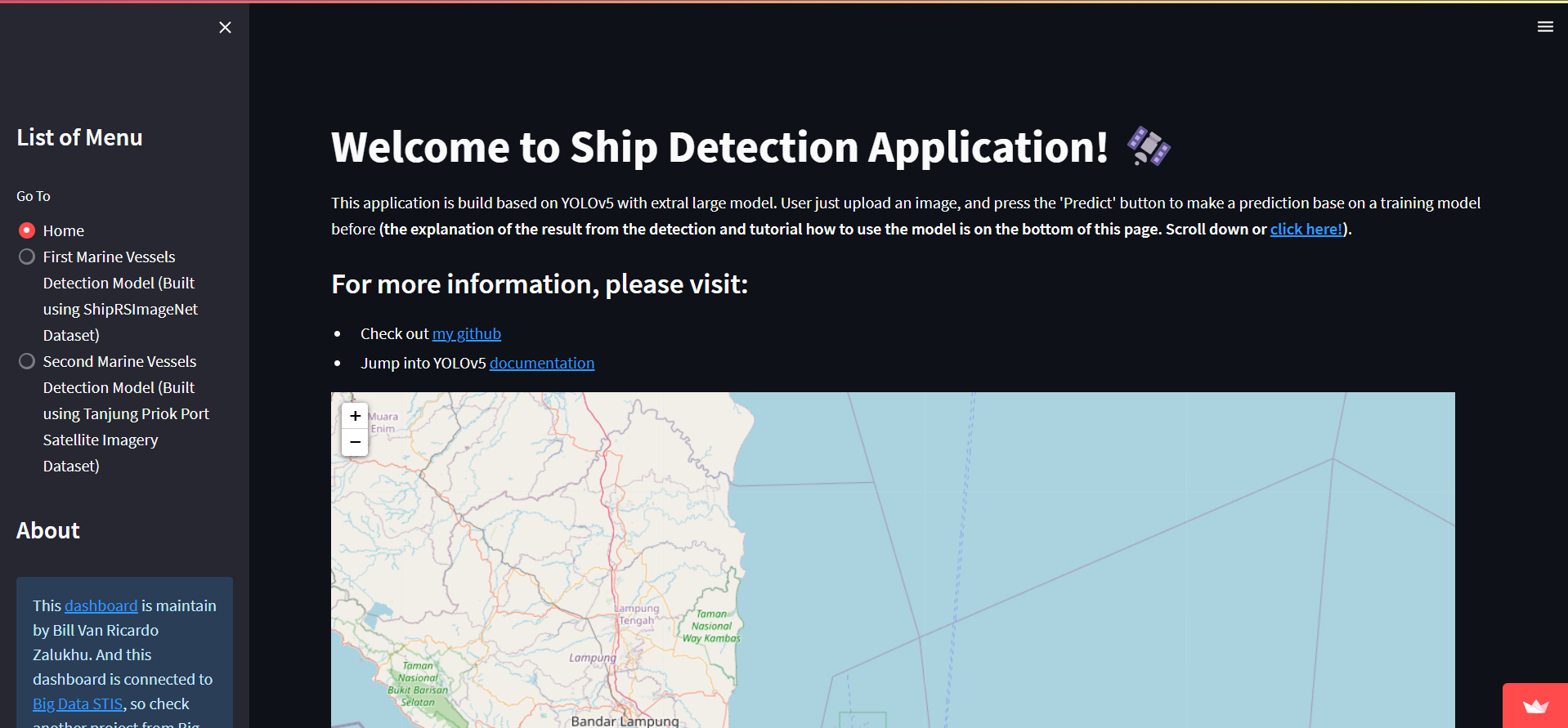
Based on Streamlit Framework
This dashboard is deploy under the Streamlit server
Click here to access the dashboard!Publication
Research results have been published on: https://ieeexplore.ieee.org/document/9994340
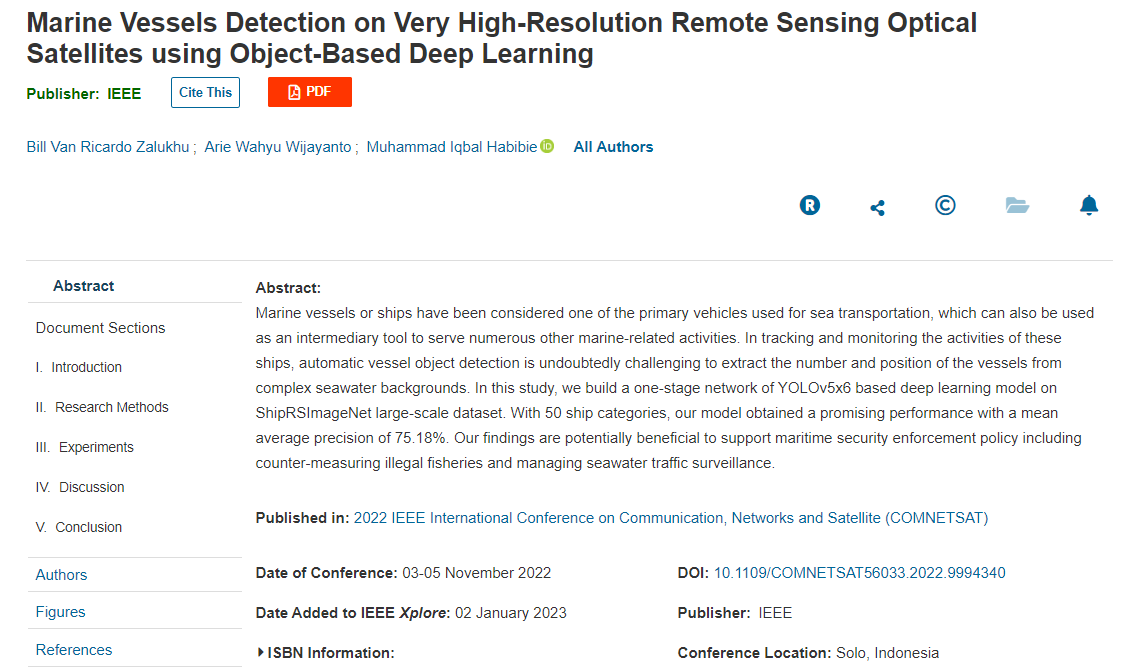
This paper get the best paper predicate in the conference

Evaluate Our Work!
For research purposes, users are expected to provide an evaluation of their experience using this prediction dashboard.